이 글의 사진 및 내용은 강의 자료에서 인용하였습니다.
Loss
Loss란 데이터와 예측값 사이의 오차를 말합니다.
예측값이 정답값과 가까우면 Loss값은 작아지고, 예측값이 정답값과 멀어질수록 Loss값이 커집니다.
다음 이미지는 3개의 Class와 Scroe값이 있습니다.

위의 예제를 이용하여 Score로부터 우리는 Loss를 구해야 합니다.
먼저 수식을 봅시다.

위 식의 ((x_{i})는 Image 데이터, ((y_{i}))는 Label 데이터를 가르킵니다.

Loss Function은 다음과 같이 정의됩니다.
데이터 세트에 대한 Loss는 example에 대한 Loss의 합계입니다.
이 강의에서는 2가지 Loss Function에 대해 배웁니다.
- SVM - Hinge Loss
- Softmax - Cross Entropy Loss
먼저 SVM Loss를 봅시다.
SVM Loss
SVM Loss의 Score 벡터는 다음과 같이 표현 할 수 있습니다.
xi는 image 데이터, W는 파라미터가 되겠습니다.

SVM의 Loss Function은 다음과 같이 정의됩니다.
max는 두 값들 중에 더 큰 값을 반환하는 함수입니다.
((s_{j}-s_{yi}+1)) 값이 0보다 크면 이 값을 반환하고, 0보다 작으면 0을 반환합니다.
그래프로 표현하면 다음과 같습니다.

그래프의 최솟값은 0이 되고 최댓값은 무한대가 됩니다.
((s_{j}))는 다른 label의 score이고, ((s_{yi})) 제대로 된 label의 score를 의미합니다.
또 위 식에서 더해준 1은 safety margin 이며 함수의 최솟값을 올려 분류의 성능을 올리는 역할을 합니다.
글로만 쓰면 이해가 힘드니 예시를 봅시다.

다음 예시에서 Cat의 경우의 Loss값을 구해봅시다.
$$ max(0,5.1−3.2+1)=2.9 $$$$ max(0,−1.7−3.2+1)=0 $$
따라서 Cat의 경우의 Loss값은 2.9가 나옵니다.
이런식으로 다른 Class Loss값을 모두 구하고 합하면 2.9+0+12.9 = 15.8이 됩니다.
데이터의 Loss값의 평균을 구하기 위해 Class의 개수로 나누어주면 최종 Loss값이 나옵니다.
$$ L=15.8/3=5.27 $$
그렇다면 Car Class의 Car의 Score가 커지면 어떻게 될까요?
Loss값은 일정할 것입니다. 다른 Class의 SCore에서 Car의 Score를 뺀다 해도 0보다 크지 않기 때문입니다.
자기 자신의 Loss 또한 포함되면 어떻게 될까요?
Loss값에 1씩 더해질 것입니다. 아래 식을 참고해주세요
$$ max(0,3.2−3.2+1)=1 $$
자기 자신의 Scroe로 Loss를 구한 경우 1의 값을 반환합니다.
각각의 Class의 Loss값이 1씩 증가하니 전체 Loss의 평균이 1 증가합니다.
일반적으로 처음 weigth값을 매우 작은값으로 초기화 합니다. 그러면 Score는 0에 매우 가까울 텐데, 이때 Safety Margin이 있으므로 위 예시에서는 초기 Loss 평균값은 2가 될것입니다.
만약 Li를 제곱을 하면?
결과적으로 매우 다르게 나올 것입니다. 제곱을 하게 되면 Linear하지 않고, Loss의 제곱의 값은 매우 크게 될 수 있습니다.
그렇다면 SVM Loss는 완벽할까요? 좀 더 생각해봅시다.
Loss를 0으로 만드는 파라미터가 과연 unique할까?
Loss를 0으로 만드는 파라미터는 되게 많을 것입니다.
Unique한 파라미터값을 지정하기위해 사용되는것이 Regularization(정규화)입니다.
Regularization (정규화)
Regularization은 모댈의 Complexity를 줄이는 방법으로, 모델의 과적합을 방지는 역할을 합니다.

λ는 Hyperpapmeter로 Regularization Strength 입니다.
λ는 Regularization의 강도를 조절하는 역할을 합니다.
Regularization에는 대표적으로 L1,L2 가 있습니다.

L1 Regularization은 모델의 가중치 중에서 작은 값들을 0으로 만들어 모델의 Complexity를 줄입니다. 따라서 불필요한 특징들을 무시하도록 합니다.
L2 Regularization은 가장 일반적인 정규화 기법으로, 모델의 가중치를 제곱합한 값을 Loss Function에 더해주는 방법입니다.
L2 Regulaization은 weight가 모두 0에 가까운 값이 되는걸 원합니다. 데이터 Loss 입장에서는 분류를 위해 weight가 0일수는 없으니 두 항이 작용하면서 데이터에 가장 fit하고 가장 최적화된 weight값을 추출하게 됩니다.
이것을 이용하면 Training error는 더 커질텐데, Test 데이터에 대한 퍼포먼스는 좋아질 것입니다.
결과적으로 Test 데이터에 Generalize 된 결과를 낼 것입니다.

따라서 L1의 경우는 가중치의 작은값을 0으로 만들기 때문에 W1을 선호하고, L2는 wegiht가 최대한 spread되어 모든 input feature를 고려하기 위해 W2를 선호합니다.
Softmax Classifier (multinomial logistic regresion)
이번에는 Softmax Classifier에 대해 알아봅시다.
다음 Classifier의Score 는 다음과 같이 정의합니다.
$$ s=(xi,W)s=(xi,W) $$
수식으로 표현하면 다음과 같이 됩니다.

위 식이 바로 Softmax function입니다.
이 함수는 입력으로 받은 벡터의 각각 원소들을 지수의 제곱으로 변환하여 합한후, 이 값을 나누어 출력합니다.
때문에 0~1사이의 Score를 반환하게 됩니다.
.

Softmax의 손실함수는 이렇게 표현되며 Cross Entropy Loss라 합니다.
Cross Entropy는 제대로된 클래스의 대한 log의 확률을 최대화 하고자 하는게 목표입니다.
다시 말하면 ((-log))의 확률을 최소화 하고자 하는것과 같은말입니다
Log함수를 취하면 0과 1 사이 값의 차이를 더 큰 차이로 표현 할 수 있습니다.
예로들어 0.99와 0.01의 경우, ((-log))를 취하면 각각 0.0101, 4.605가 됩니다.

정규화하지 않은 Loss는 큽니다. e의 지수로 계산하여 나온 Loss값의 합은 188.68 입니다.
이 값을 Loss값에 나누어 정규화하면 합이 1이 됩니다.
마지막으로 ((log))를 취해주면 Loss는 0.89로 나옵니다.
그렇다면 Softmax이 Loss값의 최댓값 최솟값은 얼마일까요?
다음 그래프를 봅시다.

Loss는 감소하는 ((log))함수입니다. 그래프의 x값의 범위(확률)는 0~1이므로 따라서 최솟값은 0이될 것이고, 최댓값은 무한대입니다.
SVM vs Softmax

다음은 SVM과 Softmax를 비교한 것입니다.
Linear Classifer 측면에서 이 설정은 동일하게 보입니다. 하지만 둘은 전혀 다릅니다.
SVM의 경우 올바른 Class의 점수와 Wrong Class 점수 사이의 Margin을 봅니다.
반대로 Softmax는 Class의 확률을 보기 때문에 다르게 작용합니다.
한 가지 예시를 봅시다.

위 상황에서 0번 Class의 Score를 약간씩 변형시키면 어떤일이 벌어질까요?
SVM의 경우에는 약간에 변화에 Loss값은 변하지 않습니다. SVM이 신경쓰는 것은 올바른 Class의 점수가 Wrong 점수보다 작아지게 되는것 입니다.
Softmax의 경우는 클래스의 확률을 올리기 원합니다. 따라서 항상 모든 인자를 고려하기 때문에 Loss값이 변합니다.

지금까지는 LossFunction에 대해 배웠습니다. 그렇다면 Loss를 최소하는 W는 어떻게 찾을수 있을까요?
바로 Optimization을 통해 최솟값을 찾을 수 있습니다.
Optimization
다음 같이 큰 골짜기가 있습니다.

Optimization은 이 큰 골짜기에서 제일 낮은 곳을 찾아가는 과정이라 비유할 수 있습니다.
즉 Loss를 minimaze 하는 wegiht를 찾는 과정입니다.
Optimization 전략은 여러가지가 있습니다.
그 중 Random Search 방법은 매우 비효율적 입니다.
랜덤하게 W값을 바꾸어 최저점을 찾기 때문에 최저점을 찾을 수 있을지 없을지도 정확하지 않습니다.
효율적인 최적화를 위해 기울기를 이용한 전략을 사용합니다.
그럼 기울기를 먼저 구해봅시다.
첫번쨰 방법은 미분을 사용하지 않고 함수의 기울기를 근사적으로 계산하는 방법입니다.
수학적으로 기울기의 수식은 다음과 같이 정의됩니다.

이렇게 수치적으로 경사를 구하는 것을 Numerical Gradient라 합니다.
이 방법은 기울기를 근사적으로만 계산할 수 있고, 시간이 오래 걸린다는 단점이 있습니다.
그래서 우리는 미분을 사용합니다.
우리는 함수에서 미분을 통해 기울기를 구할 수 있습니다.
다차원 함수의 경우는 기울기는 벡터의 형태로 나타날 것입니다.
이렇게 미분을 이용해 기울기를 구하는 방법을 Analytic Gradient라 합니다.
Analytic Gradient은 기울기 값이 정확하고 계산이 빠르다는 장점이 있습니다.
하지만 미분이 불가능한 함수에 대해서는 사용하지 못한다는 단점이 있습니다.
또한 검토할 때 Numerical Gradient 사용하여 기울기를 확인합니다. 이 방법을 Gradient Check라 합니다.
지금까지 기울기를 구하였고 이것을 이용해봅시다.
Loss는 weight의 funcion이므로 미분을 통해 Loss Function의 기울기를 구할 수 있습니다.
그리고 weight가 변할 때 Loss가 얼마나 변하는가 확인을 할 수 있습니다.
기울기가 음수인 경우는 하강하고 있음을 나타내고, 반대는 상승함을 나타냅니다.
따라서 기울기가 하강하는 쪽으로 W값을 수정하면 됩니다.
이 방법을 Gradient Descent (경사 하강법)이라 합니다.
Gradient Descent (경사 하강법)
경사 하강법은 W를 수정함으로 기울기의 음의 방향으로 계속 찾아 나가는 방법입니다.
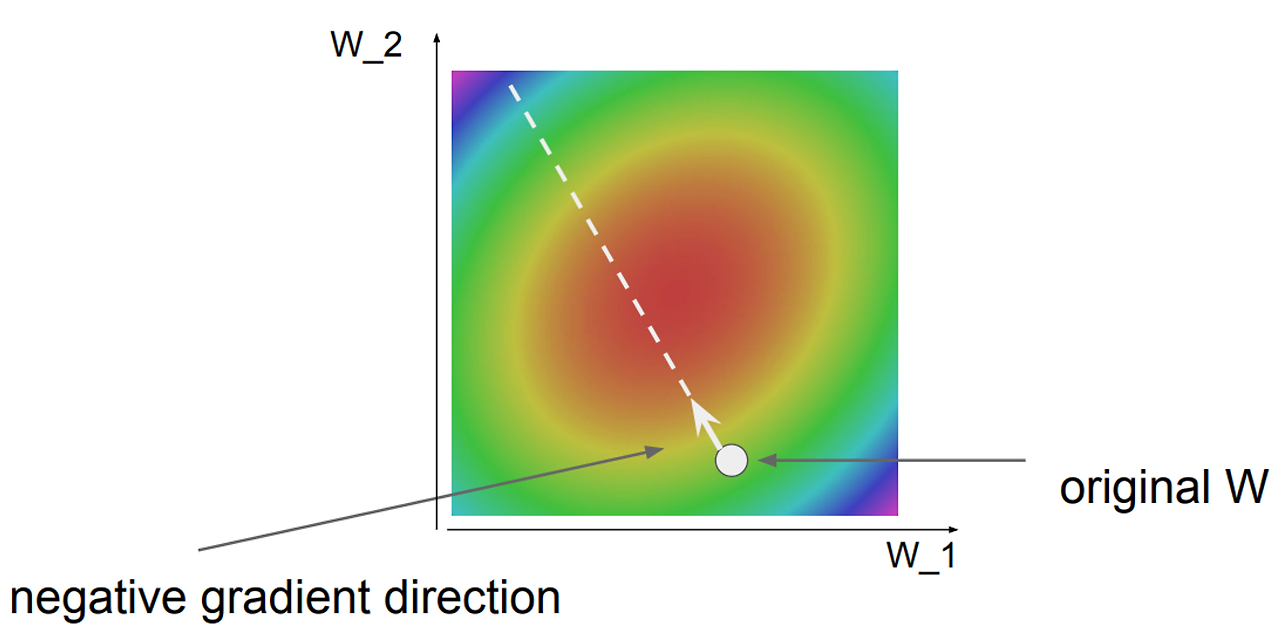
Gradient Descent의 수식은 다음과 같습니다.

α는 learning rate로, 얼마나 큰 보폭으로 업데이트 할지 정하는 파라미터 입니다.
그렇다면 learning rate는 어떻게 설정해야 할까요?
learning rate값이 너무 크다면 Loss는 증가하여 발산하게 됩니다.
하지만 반대로 너무 작으면 최적화 시간이 오래 걸린다는 단점이 있습니다.
learning rate가 높다면 Global minimum이 아닌 Local Minimum에 빠지는 경우도 있습니다.
따라서 적절한 Learning rate값을 찾기 위해 처음에는 높게 설정하고 서서히 낮추면서 찾아가야 합니다.
Descent Gradient 방법에는 여러가지가 존재합니다. 간단히 정리해보았습니다.
- Full-batch-Gradient Descent
- 모든 데이터를 한번에 처리하는 방식
- 최적화 시 정확한 방향으로 갈 확률 높음
- 대규모 데이터 셋에서는 사용이 어려움
- Mini-batch-Gradient Descent
- 데이터를 Mini-batch 단위로 처리하는 방법
- Training 데이터의 일부만 활용해 효율적이며 성능을 높임
- Mini-Batch Size는 32,64,128,같은 2의 제곱수로 가짐
- Stochastic-batch-Gradient Descent
- Mini-batch의 크기를 1로 지정
- 데이터를 한 개를 처리할 때마다 파라미터 업데이트
- 수렴 속도가 빠르지만 최적의 해를 못 찾을 수 있음
마무리
CNN이 나오기 전에 Image Classification을 어떻게 했을까요?
Image Feature

Original 이미지가 아닌 Feature를 추출 한 후 linear classfier를 적용 하였습니다.
추출 한 Feature들을 하나의 벡터처럼 이어준 후 적용하는게 일반적인 방법이였습니다.
피쳐 추출 방법에는 여러가지가 있습니다.
Color Histogram

컬러가 피쳐가 됨 이미지 내의 모든 픽셀이 컬러를 파악하는 방법입니다.
각각의 bin(검은선으로 구분)에 해당하는 색은 몇개인지 카운트 합니다.
Histogram of Oriented Gradients(HOG)

8x8 픽셀로 구성된 구역을 보면서 엣지들의 방향을 9개로 구분해서 9가지 bin에 몇개가 속하는지를 기준으로 edge orientation을 피처로 추출하는 방법입니다.
Bag of Word

Feature를 벡터로 기술하고, 모아서 사전화를 합니다. 그 후 테스트 이미지와 제일 유사한 이미지를 k-means 방식을 사용하여 찾습니다.

이처럼 전통적인 방식은 Feature를 추출하여 Classification을 하였습니다.
하지만 Neural Network의 경우 Feature 추출을 하지 않고 이미지 자체를 던지면 모델(함수)가 알아서 결과를 출력해줍니다.
'AI > CS231n' 카테고리의 다른 글
| [CS231n]Image Clsassification 정리 (2) | 2024.08.28 |
|---|